
Cherry-picking is a bigger annotation risk than hallucination
Cherry-picking in LLM cell annotation survives reference checks unlike hallucination. Learn why biased marker subsampling is the harder risk and how CyteType prevents it.
When people talk about the risks of using LLMs in biology, they almost always reach for hallucination first. The model invents a marker, names a cell type whose canonical genes aren't in the data, asserts something that simply isn't there. It's the failure everyone has a mental model for, and it's the one we worry about least.
Parashar Dhapola made this point on the Beyond Biotech podcast, and it draws the line in the right place. Hallucination tends to expose itself. If a model labels a cluster plasmacytoid dendritic cells but the panel carries no LILRA4, no IRF7, no GZMB, that annotation can be checked against what the cluster actually expresses and against reference databases, and the fabrication falls out. Standard evidence checks and cross-referencing surface the annotations that do not hold up; tedious work, but it reliably gets done.
Cherry-picking is the harder problem
Cherry-picking is the harder problem, and it's the one that should worry anyone putting an annotation into a decision.
The mechanism at cluster scale
The mechanism is easy to picture. Take a single cluster from a single-cell experiment. Differential expression yields a ranked marker panel, realistically fifty to a few hundred genes the cluster expresses above background. That panel goes to a model with one question: what are these cells? The model fixes on three or four canonical markers it recognises, settles on a confident and entirely plausible annotation, and quietly leaves the rest aside. The annotation is internally consistent, it survives a reference check, and it looks correct. Nothing in the output reveals that it rested on a biased subsample of the evidence, or which seven genes out of ten were never weighed.
This is not fabrication, which is exactly why it slips past the usual checks. The model is doing what language models do with a large input, concentrating on a few salient genes and discounting the rest, and no prompt reliably removes it. The problem compounds with scale. A single-cell dataset carries dozens to hundreds of clusters, each with its own marker panel, and the gene space the model is nominally reasoning over numbers in the hundreds of thousands of cluster-by-gene decisions. At that scale, whether it weighed all of the evidence or settled on the first plausible story stops being a rhetorical worry and becomes the central one.
Where biology makes this concrete
The biology is where this stops being abstract. Consider the exhausted-versus-effector T cell distinction that matters so much in cell therapy. A model can see CD8A and GZMB, label the cluster cytotoxic T cells, and be right about the lineage while completely missing the co-expression of TOX, PDCD1, LAG3 and TIGIT that would have flagged exhaustion. The lineage assignment holds. The functional state, which is the thing that decides whether those T cells have any firepower left in them, gets lost because the model never weighed the markers that carried it. The annotation reads correct and points the wrong way, and downstream that can mean putting effort behind a patient sample that should have been triaged out.

Figure 1: The same marker panel yields three different reads depending on whether the model fabricates, cherry-picks, or weighs every gene.
How CyteType is built against cherry-picking
This is most of why CyteType is built the way it is. Rather than trust the model to weigh a whole marker panel in one go, the work is decomposed into many bounded questions, each one narrow enough that the model cannot quietly skip most of the evidence, while programmatic steps decide what gets asked, how deep it goes, and how the answers are scored. Parashar describes it as fanning out across thousands of genes and then pruning back, and as babysitting the language models rather than trusting them. The same questions are asked in the same order, dataset after dataset, and the deterministic workflow architecture keeps a trace of what it considered and what it rejected, with the reasoning attached. The safeguard against cherry-picking comes from the structure around the model, not from the model choosing to be thorough.
More reproducible, not deterministic
The honest caveat matters here: the model's outputs are still stochastic, and LLMs are not deterministic. Saying otherwise would be the wrong thing to tell people who will check the work. What the structure provides is coverage and a trace, so every gene is looked at and the reasoning behind each annotation stays visible. The outputs are more reproducible, not reproducible, and that distinction is the whole point. We have not made a language model deterministic (Yet. Stay tuned for more on how we aim to solve this with our latest and more ambitious project in the pipeline); we have built the control flow around it so that its worst habit, quietly ignoring most of the evidence, can no longer happen unobserved.
Hallucination gets the headlines because it's vivid and easy to picture. Cherry-picking gets the decisions, because it's the failure that survives review, and that's the one worth engineering against.
Check out Beyond Biotech episode 192 with Parashar.
CyteType is available via pip install cytetype (Python) and from GitHub (R via CyteTypeR). If you're evaluating AI-based annotation tools for your single-cell pipeline, we'd welcome the conversation. Schedule a demo →
Related articles

Everyone Is Building AI Agents for Drug Discovery. We Built a Workflow for One Task. Here's Why.
Why we rebuilt CyteType as a deterministic AI workflow instead of an agent, and why that distinction matters for production cell annotation pipelines.
Read more →
What We Got Wrong About AI Agents for Cell Annotation
Running CyteType's AI agents across thousands of single-cell RNA-seq datasets in production exposed run-to-run variance, selective evidence gathering, and inconsistent depth. We rebuilt cell type annotation as a deterministic LLM workflow for reproducible, auditable results in drug discovery pipelines.
Read more →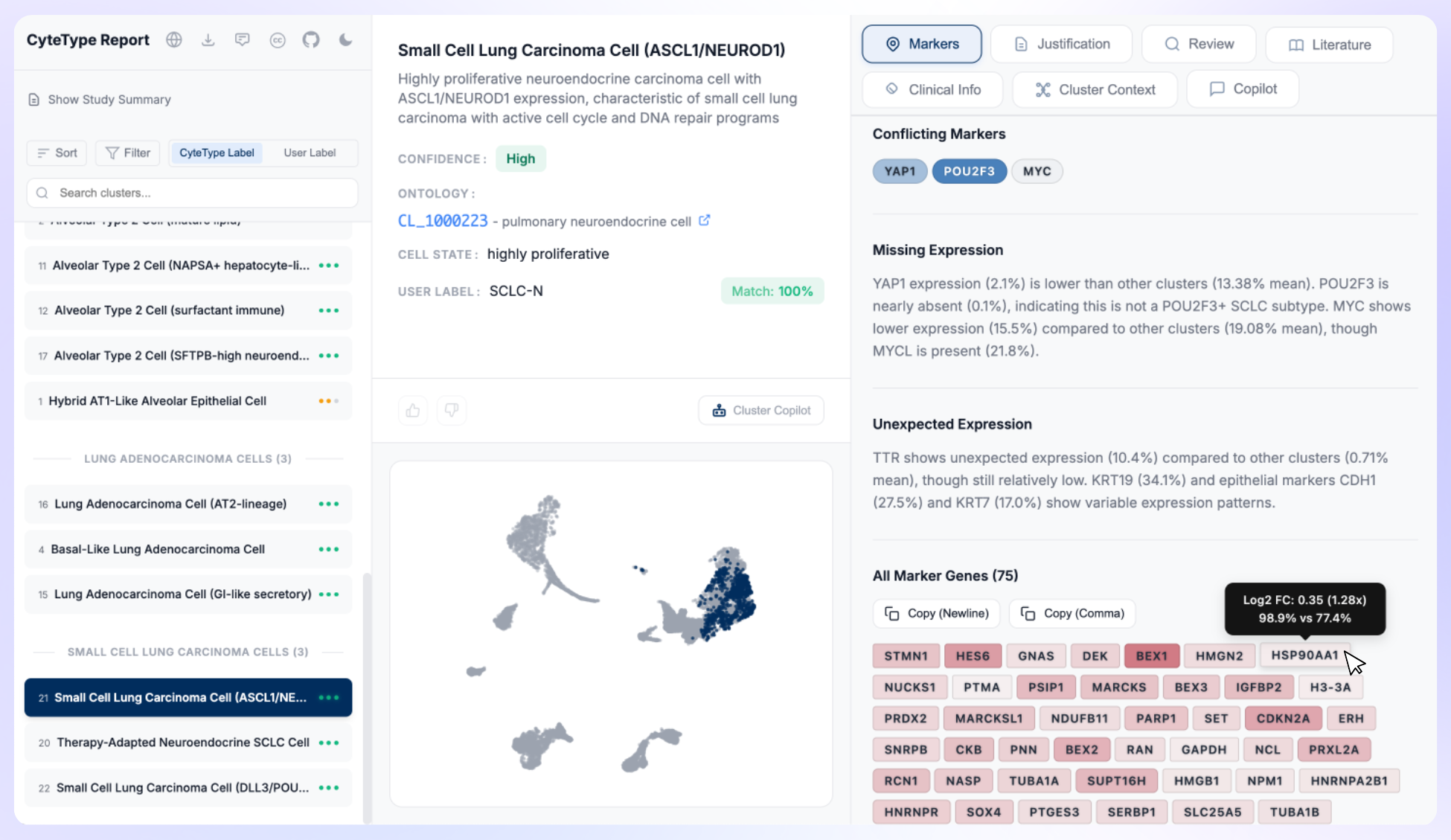
CyteType: Evidence-Based Cell Annotation with Multi-Agent AI
CyteType uses a five-agent AI framework for accurate cell type annotation in scRNA-seq data. Outperforms reference-based methods by 300%+ in benchmarking.
Read more →